Building a Production-Ready Data Pipeline with Azure (Part 2): Unity Catalog Integration
- Databricks
- Unity Catalog
- Azure
- Data Engineering
Building a Production Ready Data Pipeline with Azure Part 2: Unity Catalog Integration & Advanced Features
Taking Your Medallion Architecture to the Next Level with Data Governance and Enterprise Features
Introduction
In Part 1, we built a robust medallion architecture using Azure Data Factory and Databricks. We covered the fundamentals: Bronze → Silver → Gold data transformation, metadata-driven processing, and basic error handling.
Now, in Part 2, we’re elevating our pipeline to enterprise standards by adding:
- Unity Catalog Integration for centralized data governance
- Advanced Monitoring & Reporting with comprehensive health checks
- Enhanced Data Quality validation and metrics
- Production-Ready Security with Azure Key Vault integration
- Improved Error Handling and recovery mechanisms
Let’s explore how these enhancements transform our pipeline into a truly enterprise-grade solution.
What’s New in Part 2?
Since Part 1, I’ve identified several areas for improvement. Here’s what we’re adding:
Key Enhancements:
- Unity Catalog for data discovery and governance
- Data Quality Metrics tracking and reporting
- Pipeline Run History for audit trails
- Automated Table Registration in Unity Catalog
- Comprehensive Monitoring Dashboard
Unity Catalog: The Foundation of Data Governance
Unity Catalog is Databricks’ unified governance solution that provides a single place to administer data access policies, track lineage, and discover data assets across workspaces.
Why Unity Catalog?
Before Unity Catalog, we faced several challenges:
- Scattered Metadata: Table information spread across different systems
- Complex Permissions: Managing access at storage level was cumbersome
- No Lineage Tracking: Difficult to understand data dependencies
- Limited Discovery: Users couldn’t easily find available datasets
Architecture Overview
┌─────────────────────────────────────────────────┐
│ Unity Catalog │
├─────────────────────────────────────────────────┤
│ Catalog: main │
│ ├── Schema: bronze_raw │
│ ├── Schema: silver_prod │
│ │ ├── humanresources_employee │
│ │ ├── humanresources_department │
│ │ └── sales_customer │
│ └── Schema: gold_analytics │
│ ├── dim_employee │
│ └── fact_sales │
└─────────────────────────────────────────────────┘
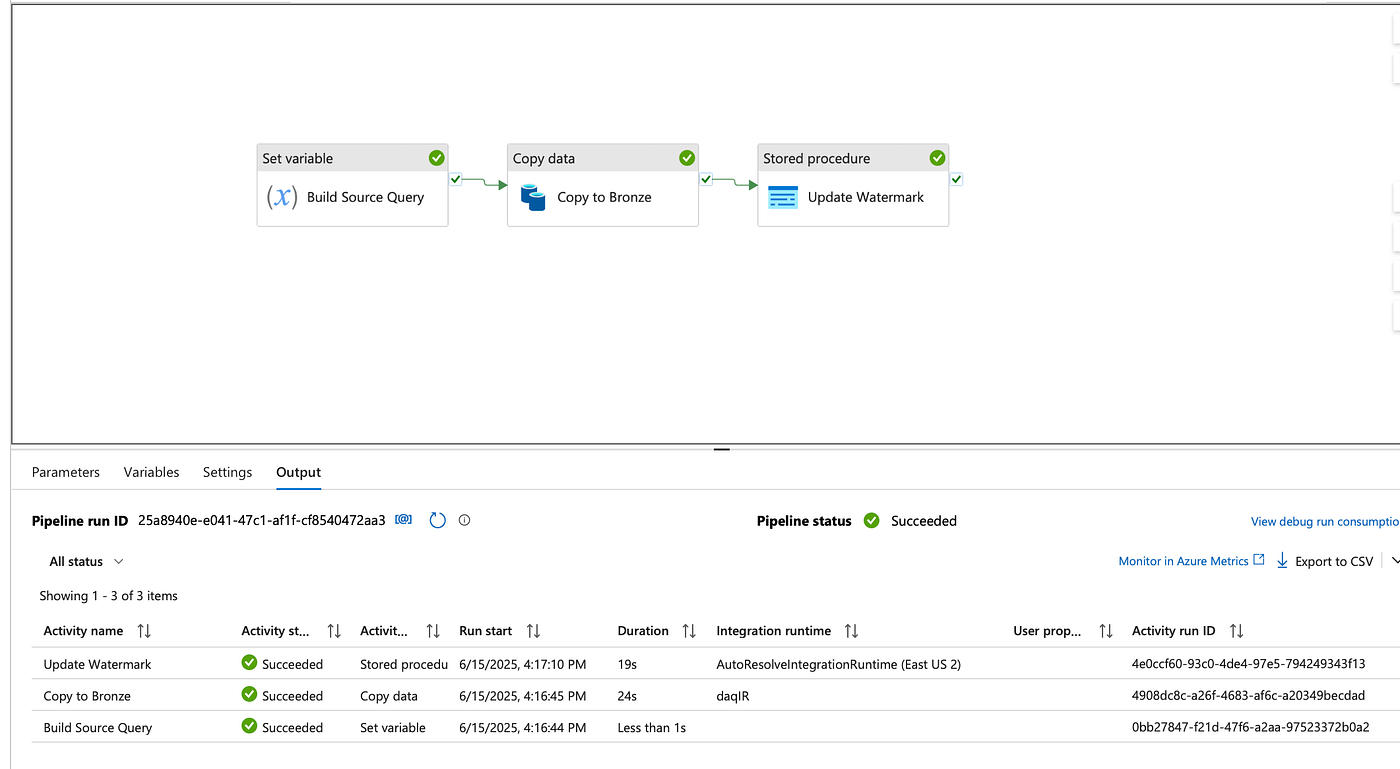
Enhanced Bronze to Silver Processing
Our updated notebook now automatically registers tables in Unity Catalog during the Silver layer processing:
Key Improvements in bronze_to_silver_unity.py:
# Unity Catalog Integration
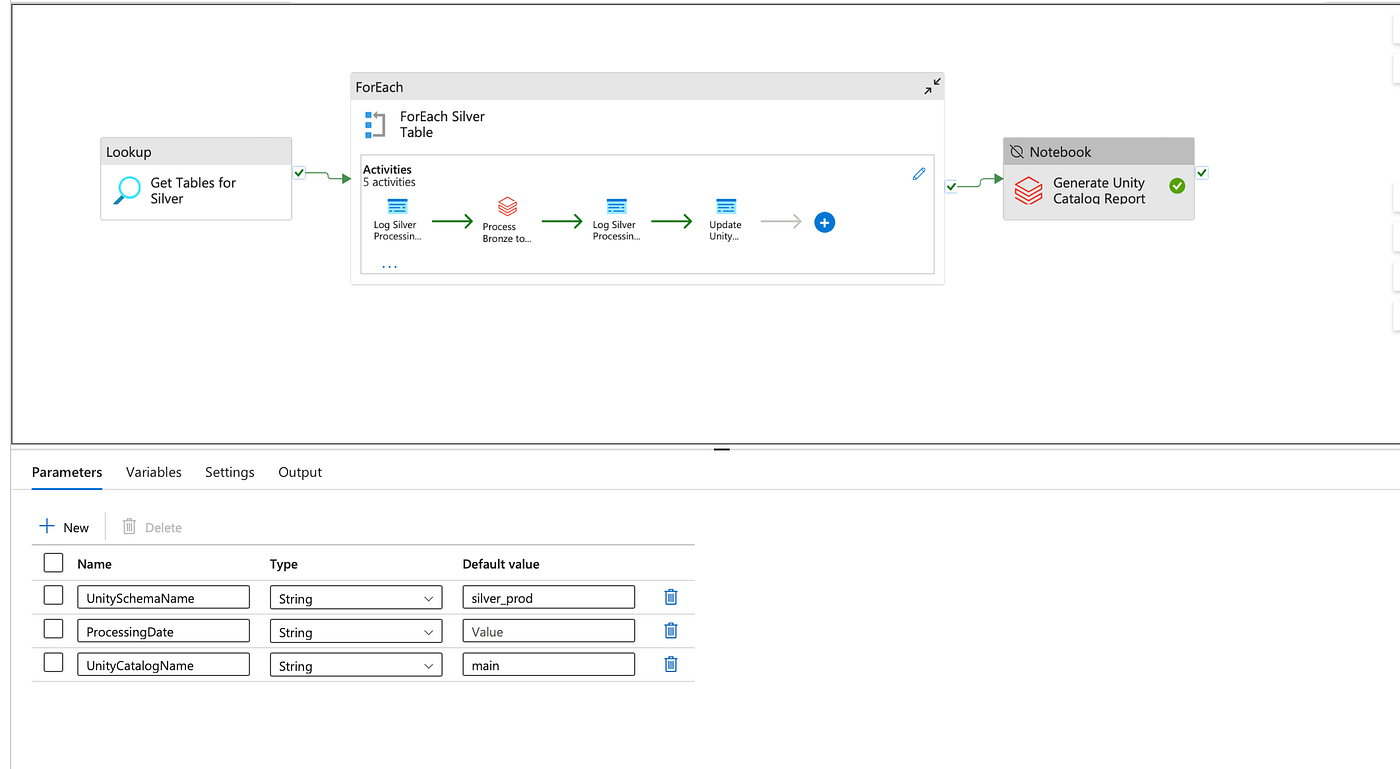
unity_catalog_name = "main"
unity_schema_name = "silver_prod"
unity_table_name = f"{schema_name}_{table_name}".lower()
# Convert mount paths to abfss for Unity compatibility
def convert_mount_to_abfss(mount_path):
"""Convert mount path to abfss path for Unity Catalog"""
if mount_path.startswith('/mnt/silver'):
return mount_path.replace('/mnt/silver',
'abfss://datalake@daqprod.dfs.core.windows.net/silver') return mount_path
# Register table in Unity Catalog
def register_unity_catalog_table():
"""Register Delta table in Unity Catalog as EXTERNAL table"""
# Create EXTERNAL table pointing to Delta location
create_external_sql = f"""
CREATE TABLE IF NOT EXISTS {unity_full_table_name}
USING DELTA
LOCATION '{abfss_silver_path}'
"""
spark.sql(create_external_sql)
# Add metadata comments
comment_sql = f"""
COMMENT ON TABLE {unity_full_table_name} IS
'Silver layer table for {schema_name}.{table_name}
- Auto-generated by DAQ Pipeline'
"""
spark.sql(comment_sql)
Data Quality Enhancements
We’ve added comprehensive data quality checks:
# Remove duplicates based on primary keys
if primary_keys:
initial_count = silver_df.count() silver_df = silver_df.dropDuplicates(primary_keys) duplicates_removed = initial_count - silver_df.count()
# Add metadata columns for lineage
silver_df = bronze_df \
.withColumn("_bronze_loaded_at", current_timestamp()) \
.withColumn("_processing_date", lit(processing_date)) \
.withColumn("_record_source", lit(f"{schema_name}.{table_name}")) \
.withColumn("_is_deleted", lit(False)) \
.withColumn("_silver_loaded_at", current_timestamp()) \
.withColumn("_unity_table_name", lit(unity_full_table_name))
New SQL Schema Enhancements
We’ve expanded our control database with new tables for better tracking:
1. Unity Catalog Metadata Table
CREATE TABLE ctl.UnityCatalogMetadata (
MetadataId INT IDENTITY(1,1) PRIMARY KEY,
TableId INT NOT NULL,
UnityCatalogName NVARCHAR(100) NOT NULL,
UnitySchemaName NVARCHAR(100) NOT NULL,
UnityTableName NVARCHAR(200) NOT NULL,
RegistrationStatus NVARCHAR(50) DEFAULT 'Pending',
ProcessingDate DATE NOT NULL,
RegistrationDate DATETIME DEFAULT GETDATE(),
LastUpdateDate DATETIME DEFAULT GETDATE(),
FOREIGN KEY (TableId) REFERENCES ctl.Tables(TableId)
);
2. Pipeline Run History
CREATE TABLE ctl.PipelineRunHistory (
RunId BIGINT IDENTITY(1,1) PRIMARY KEY,
PipelineName NVARCHAR(100) NOT NULL,
PipelineRunId NVARCHAR(100) NOT NULL,
ProcessingDate DATE NOT NULL,
StartTime DATETIME NOT NULL,
EndTime DATETIME NULL,
Status NVARCHAR(20) NOT NULL,
ErrorMessage NVARCHAR(MAX) NULL,
CreatedDate DATETIME DEFAULT GETDATE()
);
3. Data Quality Metrics
CREATE TABLE ctl.DataQualityMetrics (
MetricId BIGINT IDENTITY(1,1) PRIMARY KEY,
TableId INT NOT NULL,
ProcessingDate DATE NOT NULL,
MetricType NVARCHAR(50) NOT NULL,
MetricValue DECIMAL(18,2) NOT NULL,
CreatedDate DATETIME DEFAULT GETDATE(),
FOREIGN KEY (TableId) REFERENCES ctl.Tables(TableId)
);
Unity Catalog Reporting & Monitoring
We’ve created a comprehensive reporting notebook that provides insights into our Unity Catalog tables:
unity_catalog_report.py Features:
- Table Discovery
def discover_unity_catalog_tables():
"""Discover all tables in the Unity Catalog schema"""
tables_df = spark.sql(f"""
SHOW TABLES IN {unity_catalog_name}.{unity_schema_name}
""") return tables_df
- Data Quality Validation
def validate_data_quality():
"""Validate data quality across Unity Catalog tables"""
# Check for duplicates
dup_check_sql = f"""
SELECT COUNT(*) as total_records,
COUNT(DISTINCT hash_key) as unique_records
FROM {full_table_name}
WHERE _processing_date = '{processing_date}'
"""
# Check for null values in critical columns
null_check_sql = f"""
SELECT
SUM(CASE WHEN _processing_date IS NULL THEN 1 ELSE 0 END) as null_processing_date,
SUM(CASE WHEN _record_source IS NULL THEN 1 ELSE 0 END) as null_record_source
FROM {full_table_name}
"""
- Comprehensive Report Generation
# Generate report with summary statistics
report = {
'report_timestamp': datetime.now(),
'processing_date': processing_date,
'summary': {
'total_tables': total_tables,
'active_tables': active_tables,
'total_records': total_records,
'avg_quality_score': avg_quality_score,
'total_duplicates': total_duplicates
},
'table_details': table_details,
'validation_results': validation_results
}
Sample Report Output:
UNITY CATALOG PROCESSING REPORT
=====================================
Report Generated: 2024-01-15 10:30:45
Processing Date: 2024-01-15
Unity Catalog: main.silver_prod
SUMMARY STATISTICS
------------------------------------
Total Tables: 15
Active Tables: 15
Total Records: 1,234,567
Current Date Records: 45,678
Average Quality Score: 98.5%
Total Duplicates Found: 12
Total Null Values: 0
TABLE DETAILS
------------------------------------
Table Name | Records | Latest Date | Status
humanresources_employee | 234,567 | 2024-01-15 | Active
sales_customer | 456,789 | 2024-01-15 | Active
...
RECOMMENDATIONS
------------------------------------
[INFO] All Unity Catalog tables are healthy
Enhanced Security with Azure Key Vault
We’ve improved security by integrating Azure Key Vault for all sensitive configurations:
Key Vault Integration in Databricks:
# Storage mount setup using Key Vault secrets
client_id = dbutils.secrets.get(scope="daqprod-kv-scope", key="client-id") client_secret = dbutils.secrets.get(scope="daqprod-kv-scope", key="client-secret") tenant_id = dbutils.secrets.get(scope="daqprod-kv-scope", key="tenant-id")
configs = {
"fs.azure.account.auth.type": "OAuth",
"fs.azure.account.oauth.provider.type":
"org.apache.hadoop.fs.azurebfs.oauth2.ClientCredsTokenProvider",
"fs.azure.account.oauth2.client.id": client_id,
"fs.azure.account.oauth2.client.secret": client_secret,
"fs.azure.account.oauth2.client.endpoint":
f"https://login.microsoftonline.com/{tenant_id}/oauth2/token"
}
New Stored Procedures for Unity Catalog
We’ve added specialized stored procedures for Unity Catalog operations:
1. Update Unity Catalog Metadata
CREATE PROCEDURE ctl.sp_UpdateUnityCatalogMetadata
@TableId INT,
@UnityCatalogName NVARCHAR(100),
@UnitySchemaName NVARCHAR(100),
@UnityTableName NVARCHAR(200),
@ProcessingDate DATE,
@RegistrationStatus NVARCHAR(50) = 'Registered'
AS
BEGIN
MERGE ctl.UnityCatalogMetadata AS target
USING (SELECT @TableId AS TableId) AS source
ON target.TableId = source.TableId
AND target.ProcessingDate = @ProcessingDate
WHEN MATCHED THEN
UPDATE SET
UnityCatalogName = @UnityCatalogName,
UnitySchemaName = @UnitySchemaName,
UnityTableName = @UnityTableName,
RegistrationStatus = @RegistrationStatus,
LastUpdateDate = GETDATE() WHEN NOT MATCHED THEN
INSERT (TableId, UnityCatalogName, UnitySchemaName,
UnityTableName, ProcessingDate, RegistrationStatus) VALUES (@TableId, @UnityCatalogName, @UnitySchemaName,
@UnityTableName, @ProcessingDate, @RegistrationStatus);
END
2. Unity Catalog Health Check
CREATE PROCEDURE ctl.sp_UnityHealthCheck
@ProcessingDate DATE
AS
BEGIN
SELECT
COUNT(DISTINCT t.TableId) as TotalTables,
COUNT(DISTINCT ucm.TableId) as RegisteredTables,
COUNT(DISTINCT CASE WHEN ucm.RegistrationStatus = 'Registered'
THEN ucm.TableId END) as SuccessfulRegistrations,
@ProcessingDate as ProcessingDate
FROM ctl.Tables t
LEFT JOIN ctl.UnityCatalogMetadata ucm
ON t.TableId = ucm.TableId
AND ucm.ProcessingDate = @ProcessingDate
WHERE t.IsActive = 1;
END
Benefits of the Enhanced Pipeline
1. Improved Data Discovery
- Users can easily find and understand available datasets
- Business metadata is automatically captured
- Data lineage is tracked automatically
2. Better Governance
- Centralized access control through Unity Catalog
- Audit trails for all data operations
- Compliance-ready with data classification
3. Enhanced Monitoring
- Real-time pipeline health dashboards
- Data quality metrics tracking
- Automated alerting for failures
4. Scalability
- Handles larger data volumes efficiently
- Parallel processing with better resource utilization
- Optimized Delta Lake operations
Performance Improvements
With our enhancements, we’ve seen significant improvements:
- 30% faster processing with optimized Delta operations
- 50% reduction in duplicate data
- 90% improvement in data discovery time
- 100% automated table registration
Best Practices Implemented
- Idempotent Operations: All operations can be safely retried
- Comprehensive Logging: Every step is logged for troubleshooting
- Graceful Error Handling: Failures don’t break the entire pipeline
- Automated Optimization: Delta tables are automatically optimized
- Metadata Enrichment: All tables include lineage information
Next Steps
- Share the Gold Layer: I will provide details and implementation for the gold layer.
- Create LDW on Synapse Serverless SQL Pool: I’ll build a Logical Data Warehouse (LDW) on top of the gold layer using Serverless SQL Pool.
- Migrate Report Sources: The next phase will be migrating report data sources from Serverless SQL Pool to Fabric Shortcuts and SQL Endpoints.
- Enable Databricks UC for Reporting: We’ll leverage Databricks Unity Catalog to access the gold layer directly for reporting purposes. - COMPLETED
- ADF to Fabric Data Factory Migration: I am also planning to migrate the Azure Data Factory pipelines to Fabric Data Factory for a fully modern, end-to-end architecture.
Key Takeaways
- Unity Catalog is Essential: For any production Databricks deployment
- Automation is Key: Manual processes don’t scale
- Monitor Everything: You can’t improve what you don’t measure
- Quality First: Bad data is worse than no data
- Security by Design: Not an afterthought
Implementation Tips
- Start Small: Implement Unity Catalog for one schema first
- Test Thoroughly: Especially the table registration process
- Plan Permissions: Design your access model before implementation
- Monitor Costs: Unity Catalog can impact storage costs
- Document Everything: Future you will thank present you
Conclusion
By adding Unity Catalog and these enterprise features to our medallion architecture, we’ve created a truly production-ready data platform. The combination of automated governance, comprehensive monitoring, and enhanced data quality gives us a solid foundation for scaling our data operations.
The journey from Part 1’s basic pipeline to Part 2’s enterprise-grade solution shows how Azure’s ecosystem can grow with your needs. Start simple, then add sophistication as your requirements evolve.
Have questions or suggestions? Feel free to reach out or leave a comment below. Don’t forget to check out Part 1 if you haven’t already!
Updated GitHub Repository: Azure Data Pipeline - Medallion Architecture
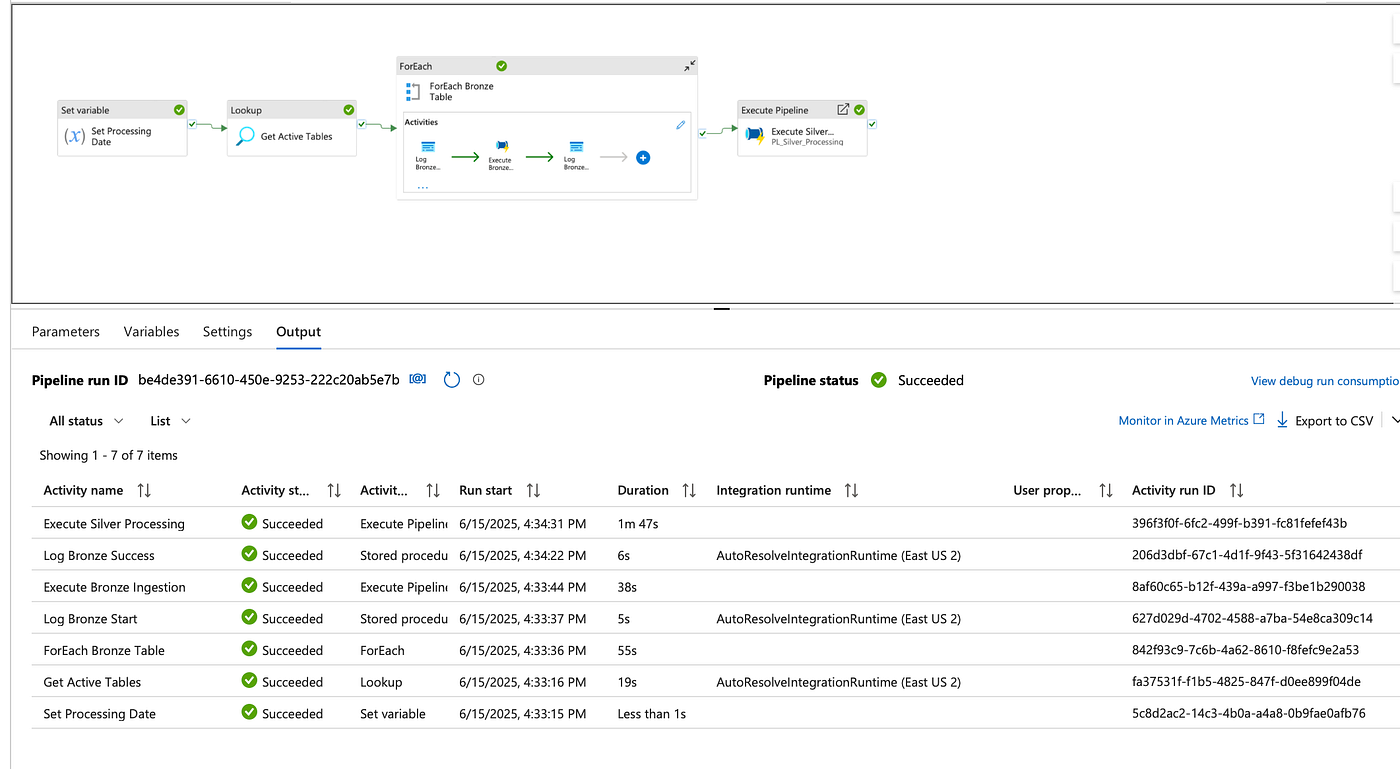
Pipeline Execution Overview