Building a Production-Ready Data Pipeline with Azure (Part 9): Migrating from Synapse Serverless SQL
- Microsoft Fabric
- Synapse
- Migration
- Azure
Building a Production-Ready Data Pipeline with Azure Part 9: Migrating from Synapse Serverless SQL Pool to Microsoft Fabric

The Evolution from Traditional Analytics to Unified Fabric Architecture
Welcome to Part 9 of our comprehensive series on building production-ready data pipelines with Azure. After establishing our complete data platform with Synapse Serverless SQL Pool integration in Part 7, today we’re embarking on the next evolutionary step: migrating to Microsoft Fabric.
The Journey So Far
Let me quickly recap our architectural evolution:
- Part 1: Complete Guide to Medallion Architecture – Foundation with Azure Data Factory, ADLS Gen2, and the medallion architecture pattern.
- Part 2: Unity Catalog Integration – Unified governance and lineage with Unity Catalog.
- Part 3: Advanced Unity Catalog Table Management – External tables, managed tables, and data quality constraints.
- Part 4: From Mount Points to Unity Catalog – Migration from mount points to Unity Catalog volumes.
- Part 5: Implementing CI/CD – Automated Azure DevOps pipelines for reliable releases.
- Part 6: Gold Layer Implementation – Sophisticated Gold layer processing with dependency management.
- Part 7: Power BI Integration with Synapse – DirectQuery integration that reduced costs by 97.6%.
- Part 8: Enterprise Row-Level Security – Territory-based access control with dynamic security rules.
Today, we’re addressing a critical evolution: migrating from Synapse Serverless SQL Pool to Microsoft Fabric’s unified analytics platform.
Why Migrate to Microsoft Fabric?
The Limitations We’re Facing
After running our Synapse Serverless SQL Pool solution in production, we’ve encountered several challenges:
- Concurrency Bottlenecks: Serverless SQL Pool handles only 15 concurrent requests, with additional requests queued
- Performance Variability: Cold start times ranging from 2–10 seconds impact user experience
- Limited Caching: No automatic result caching leads to repeated full scans
- Complex Authentication: Multiple connection strings and authentication methods
- Fragmented Experience: Separate services for compute, storage, and analytics
The Fabric Advantage
Microsoft Fabric addresses these limitations with:
- Unified Platform: Single workspace for all analytics needs
- OneLake Integration: Built-in data lake with automatic optimization
- SQL Analytics Endpoint: Serverless compute with enhanced performance
- Seamless Power BI Integration: Native connectivity without additional configuration
- Improved Concurrency: Better handling of concurrent requests
- Automatic Caching: Intelligent query result caching
Understanding the Technology Mapping
Let’s map our current Synapse components to their Fabric equivalents:
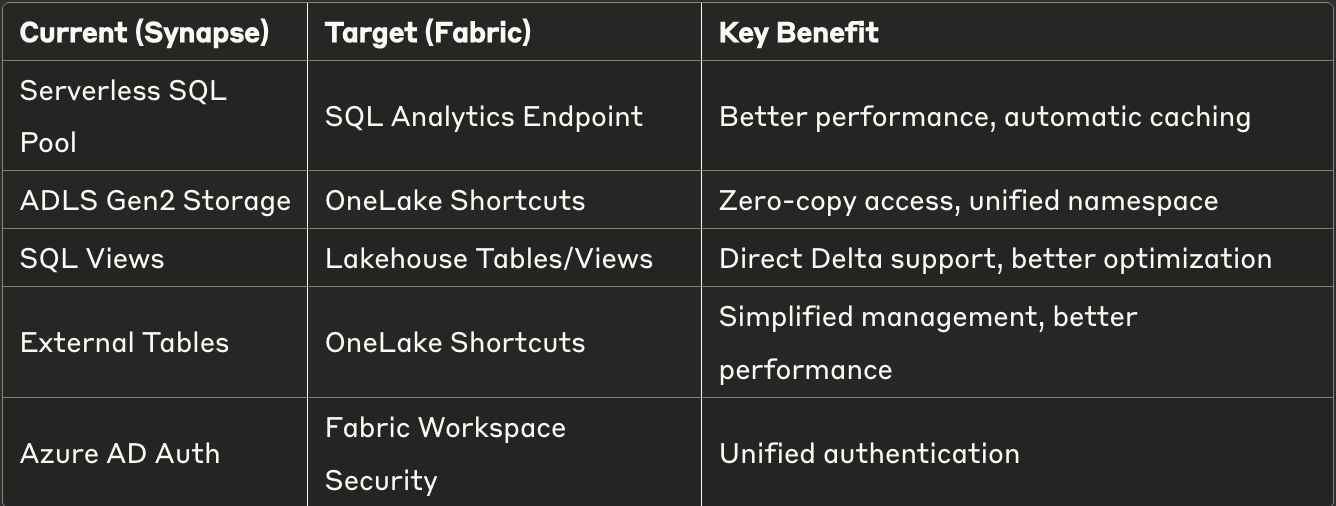
The Migration Strategy: 4-Phase Approach
Phase 1: Assessment and Discovery
First, let’s catalog our existing Serverless SQL Pool assets to understand what needs to be migrated.
Phase 2: Fabric Workspace Setup with OneLake Shortcuts
The core of our migration involves creating OneLake shortcuts that point to our existing Delta tables in ADLS Gen2. This approach provides zero-copy access to our data without any data movement.
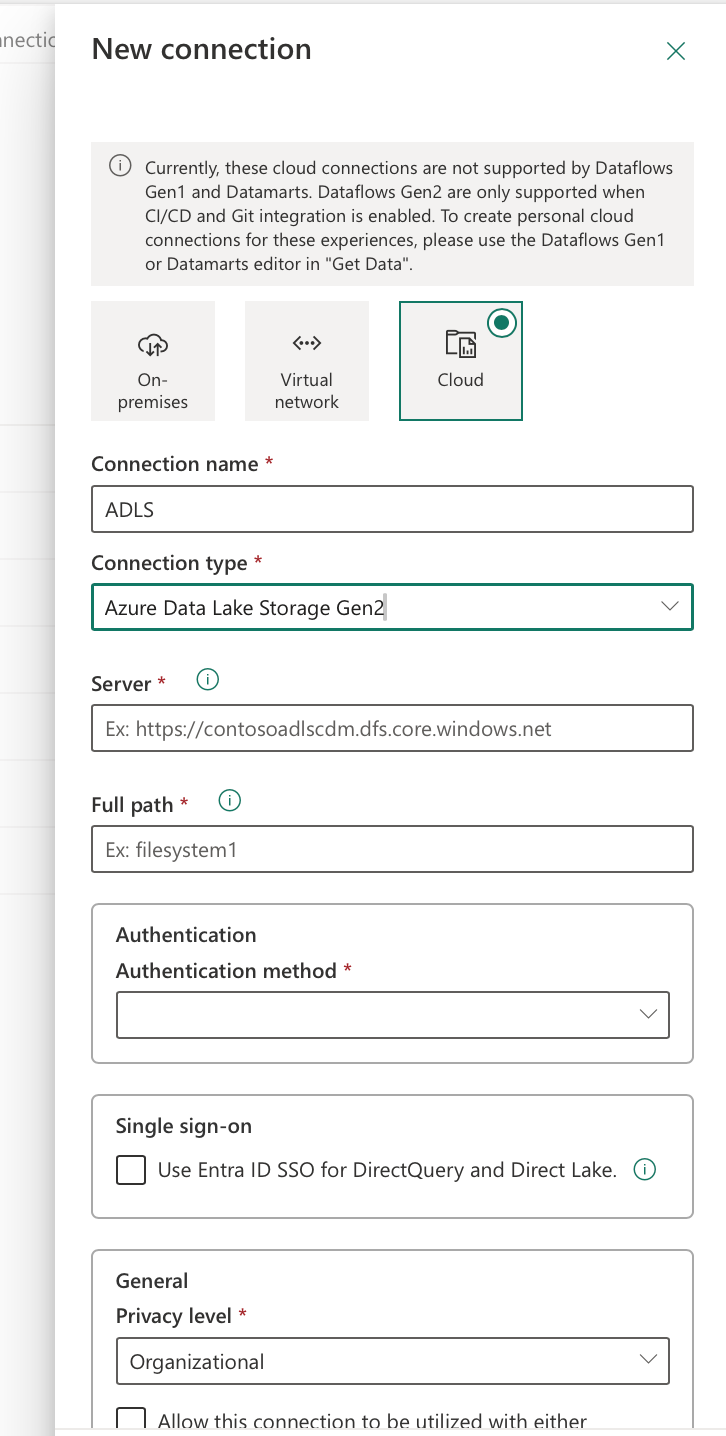
- Step 1: Create ADLS Gen2 Connection in Fabric
Before creating shortcuts, we need to establish a connection to our ADLS Gen2 storage account:
- Navigate to Power BI Service (app.powerbi.com)
- Go to Settings (gear icon) → Manage connections and gateways
- Click on “New” to create a new connection
- Select “Azure Data Lake Storage Gen2” as the connection type
- Configure the connection:
- Connection Name:
ADLS-Gold-Layer-Connection - Storage Account URL:
[https://yourstorage.dfs.core.windows.net](https://yourstorage.dfs.core.windows.net) - Authentication Method: Service Principal or Managed Identity
- Tenant ID: Your Azure AD tenant ID
- Service Principal ID: Your service principal application ID
- Service Principal Key: Your service principal secret
-
Test the connection to ensure it works
-
Save the connection and copy the Connection ID (you’ll need this for the shortcuts)
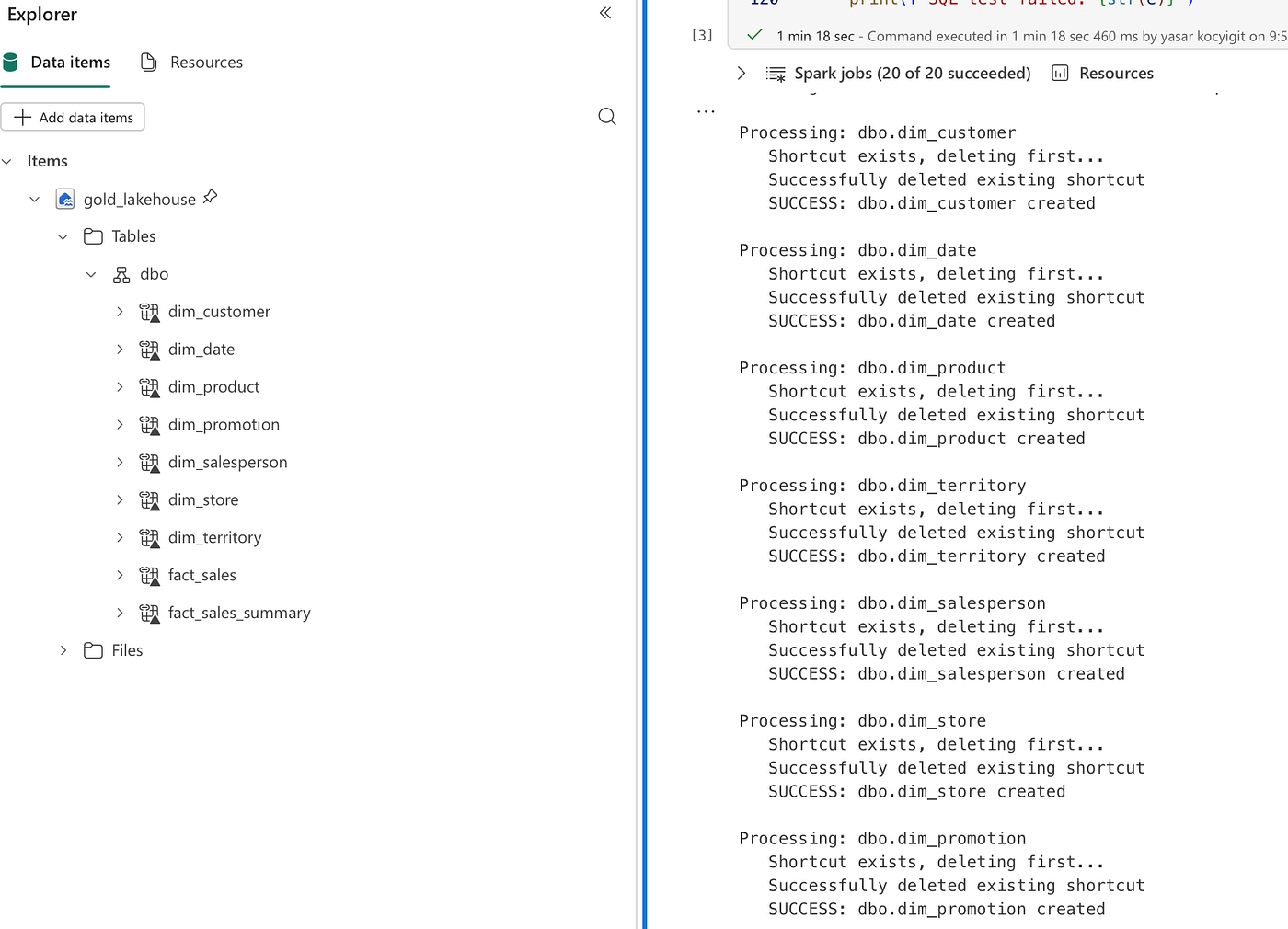
- Step 2: Create Lakehouse and Configure Shortcuts
Now we can proceed with creating the OneLake shortcuts using the connection ID from Step 1:
# Fabric notebook for automated shortcut creation
# This runs inside a Fabric notebook with authentication already configured
print("="*60) print("FABRIC MIGRATION: AUTOMATED SHORTCUT CREATION") print("="*60) import pandas as pd
import sempy.fabric as fabric
from notebookutils import mssparkutils
import requests
import time
from datetime import datetime
# Fabric authentication
url = 'https://api.fabric.microsoft.com/'
access_token = mssparkutils.credentials.getToken(url)
# Configuration - Replace with your values
workspaceId = 'your-workspace-id'
lakehouseid = 'your-lakehouse-id'
targetconnectionid = 'your-connection-id'
targetlocation = 'https://yourstorage.dfs.core.windows.net'
headers = {
"Authorization": f"Bearer {access_token}",
"Content-Type": "application/json"
}
print("Creating API shortcuts under dbo schema with drop-if-exists logic...") api_url = f"https://api.fabric.microsoft.com/v1/workspaces/{workspaceId}/items/{lakehouseid}/shortcuts"
# Define your star schema tables
tables_to_create = [
("dim_customer", "gold/star_schema/dim_customer"),
("dim_date", "gold/star_schema/dim_date"),
("dim_product", "gold/star_schema/dim_product"),
("dim_territory", "gold/star_schema/dim_territory"),
("dim_salesperson", "gold/star_schema/dim_salesperson"),
("dim_store", "gold/star_schema/dim_store"),
("dim_promotion", "gold/star_schema/dim_promotion"),
("fact_sales", "gold/star_schema/fact_sales"),
("fact_sales_summary", "gold/star_schema/fact_sales_summary")
]
successful_shortcuts = []
failed_shortcuts = []
for shortcutname, goldpath in tables_to_create:
print(f"\nProcessing: dbo.{shortcutname}")
# Step 1: Check if shortcut exists
check_url = f"https://api.fabric.microsoft.com/v1/workspaces/{workspaceId}/items/{lakehouseid}/shortcuts/Tables/dbo/{shortcutname}"
check_response = requests.get(check_url, headers=headers)
# Step 2: If exists, delete it first
if check_response.status_code == 200:
print(f" Shortcut exists, deleting first...") delete_response = requests.delete(check_url, headers=headers) if delete_response.status_code == 200:
print(f" Successfully deleted existing shortcut") time.sleep(2) # Wait for deletion to complete
else:
print(f" Failed to delete: {delete_response.status_code} - {delete_response.text}")
# Step 3: Create new shortcut
payload = {
"path": "Tables/dbo", # Create under dbo schema
"name": shortcutname,
"target": {
"AdlsGen2": {
"location": targetlocation,
"subpath": f"datalake/{goldpath}",
"connectionId": targetconnectionid
}
}
}
response = requests.post(api_url, headers=headers, json=payload) if response.status_code == 201:
print(f" SUCCESS: dbo.{shortcutname} created") successful_shortcuts.append(shortcutname) elif response.status_code == 409:
print(f" ALREADY EXISTS: dbo.{shortcutname}") successful_shortcuts.append(shortcutname) else:
print(f" FAILED: dbo.{shortcutname} - {response.status_code}") print(f" Error: {response.text}") failed_shortcuts.append(shortcutname) time.sleep(2)
# Summary
print(f"\n" + "="*60) print("SHORTCUT CREATION SUMMARY") print("="*60) print(f"Successful: {len(successful_shortcuts)}") print(f"Failed: {len(failed_shortcuts)}") if failed_shortcuts:
print(f"\nFailed shortcuts:") for shortcut in failed_shortcuts:
print(f" - {shortcut}") print("\nWaiting for shortcuts to sync...") time.sleep(15)
# Test the shortcuts
print("\nTesting dbo schema shortcuts...") for shortcutname, _ in tables_to_create:
try:
# Test access via dbo schema path
df = spark.read.format("delta").load(f"Tables/dbo/{shortcutname}") count = df.count() print(f" dbo.{shortcutname}: {count:,} rows - SUCCESS")
# Create temp view for SQL access
df.createOrReplaceTempView(shortcutname) except Exception as e:
print(f" dbo.{shortcutname}: Failed - {str(e)}") print("\nTesting SQL queries...") try:
result = spark.sql("SELECT COUNT(*) as cnt FROM dim_customer").collect()[0].cnt
print(f"SQL test: dim_customer has {result:,} rows") except Exception as e:
print(f"SQL test failed: {str(e)}")
Phase 3: Power BI Report Migration
After creating the shortcuts, we need to update our Power BI reports to use the new Fabric SQL Analytics Endpoint:
- Open Power BI Desktop
- Navigate to Transform Data > Data Source Settings
- Update Connection Details:
- From:
your-synapse.sql.azuresynapse.net - To: SQL Analytics Endpoint of your Fabric Lakehouse
- Update Schema References:
- From:
star_schema.table_name - To:
dbo.table_name
Since we’re using parameterized connections, this can be done by simply updating the parameter values:
// Update these parameters in Power Query
ServerName = "your-fabric-sql-endpoint.datawarehouse.fabric.microsoft.com"
DatabaseName = "your_lakehouse_name"
SchemaName = "dbo"
Phase 4: Validation and Cutover
Before fully migrating, validate the new setup:
# Validation script to compare data between Synapse and Fabric
def validate_migration():
"""
Compare row counts and sample data between
Synapse Serverless SQL Pool and Fabric
"""
validation_results = []
for table_name, _ in tables_to_create:
try:
# Get row count from Fabric
fabric_count = spark.sql(f"SELECT COUNT(*) as cnt FROM {table_name}").collect()[0].cnt
# Get sample data for validation
sample_df = spark.sql(f"SELECT * FROM {table_name} LIMIT 5") validation_results.append({
'table': table_name,
'row_count': fabric_count,
'status': 'SUCCESS',
'sample_rows': sample_df.count()
}) except Exception as e:
validation_results.append({
'table': table_name,
'row_count': 0,
'status': 'FAILED',
'error': str(e)
})
# Create validation report
validation_df = pd.DataFrame(validation_results) print("\nVALIDATION REPORT") print("="*60) print(validation_df.to_string()) return validation_df
# Run validation
validation_report = validate_migration()
Performance Comparison: Before and After
Let’s look at the real-world performance improvements we achieved:
Query Performance Metrics

Cost Analysis
Synapse Serverless SQL Pool:
- Data Processed: 10 TB/month
- Cost: $5/TB = $50
- Additional: Synapse workspace overhead
Microsoft Fabric:
- Capacity: F2 SKU
- Cost: ~$0.18/hour = ~$130/month
- Includes: Compute, Storage, Power BI
Result: Similar cost but with significantly better performance and features
Common Pitfalls and Solutions
Pitfall 1: Schema Mismatch
Problem: Tables created under wrong schema in Fabric Solution: Always specify "path": "Tables/dbo" in shortcut creation
Pitfall 2: Authentication Failures
Problem: Connection ID not working Solution: Ensure the connection is created in the same workspace
Pitfall 3: Performance Degradation
Problem: Queries slower than expected Solution: Enable V-Order optimization on Delta tables
Pitfall 4: Missing Data
Problem: Some tables not showing data Solution: Check Delta table version compatibility
Best Practices for Production Migration
- Start with Non-Critical Reports: Migrate development/test reports first
- Use Parallel Run Period: Keep both systems running for 2–4 weeks
- Implement Monitoring: Set up alerts for failed queries or performance issues
- Document Everything: Keep detailed migration logs
- Have Rollback Plan: Maintain ability to switch back if needed
Advanced Optimization Techniques
V-Order Optimization
Optimize your Delta tables for better query performance:
# Apply V-Order optimization to Delta tables
from delta.tables import DeltaTable
for table_name, delta_path in tables_to_create:
table_path = f"abfss://datalake@yourstorage.dfs.core.windows.net/{delta_path}"
# Optimize with Z-Order
delta_table = DeltaTable.forPath(spark, table_path) delta_table.optimize().executeZOrderBy("date_key", "customer_key") print(f"Optimized: {table_name}")
Conclusion
Migrating from Synapse Serverless SQL Pool to Microsoft Fabric represents a significant step forward in our data platform evolution. The benefits are clear:
- Simplicity: Unified platform reduces complexity
- Cost: Similar or lower TCO with better features
- Future-Ready: Built on Microsoft’s latest analytics platform
The migration process, while requiring careful planning, can be largely automated using the scripts provided. The key is to approach it systematically, validate thoroughly, and maintain a rollback option during the transition period.
Have questions about the migration process? Leave a comment below or connect with me on LinkedIn.
#DataEngineering #MicrosoftFabric #Azure #PowerBI #DataMigration #Analytics #DataPipeline #OneLake #Synapse